关于树莓派的语音识别, 网上绝大部分是介绍的使用在线的API来进行识别的。前几天遇到一个要在树莓派上实现离线语音识别的需求,于是便有了这篇文章。
通过前期调研, 发现离线的语音识别有科大讯飞的离线识别和kaldi等方案,讯飞的离线语音识别目前只提供了Android的SDK, 无法在树莓派上运行,
kaldi作为一个流行的开源的语音识别框架,是目前比较好的方案。
太长不看
如果网络不好或者不想等待很长的编译时间, 可直接下载我的制作好的镜像:
1 | docker run -d -p 2700:2700 hsxsix/rpi-kaldi-cn:latest |
(编译日期:2020-03-21)
交叉编译
在树莓派上搭建kaldi离线语音识别系统(交叉编译)这篇文章详细的介绍了如何编译一个适用于树莓派的kaldi, 但对于大部分人来说交叉编译是比较复杂的。
docker部署
那么有没有简单的呢?当然有了)基于Kaldi和Vosk-API的高精度的离线语音识别的服务,支持四种主要通信协议-MQTT,GRPC,WebRTC和Websocket。
客户端可使用C/C++, python, java,golang,PHP,Android等,并提供了对应的example code,
vosk-server支持docker部署,在普通X86_64的计算机上,一行命令即可完成部署:
1 | docker run -d -p 2700:2700 alphacep/kaldi-en:latest |
对于中文语音识别,使用kaldi-cn镜像:
1 | docker run -d -p 2700:2700 alphacep/kaldi-cn:latest |
build镜像
以上镜像是专门适用于X86_64平台的,在树莓派上, 是无法直接docker run的。
说到底还是需要我们自己编译kaldi。不过在vosk-server这个项目里, 作者提供了Dockerfile文件, 我们可以自己在树莓派上从头制作一个镜像: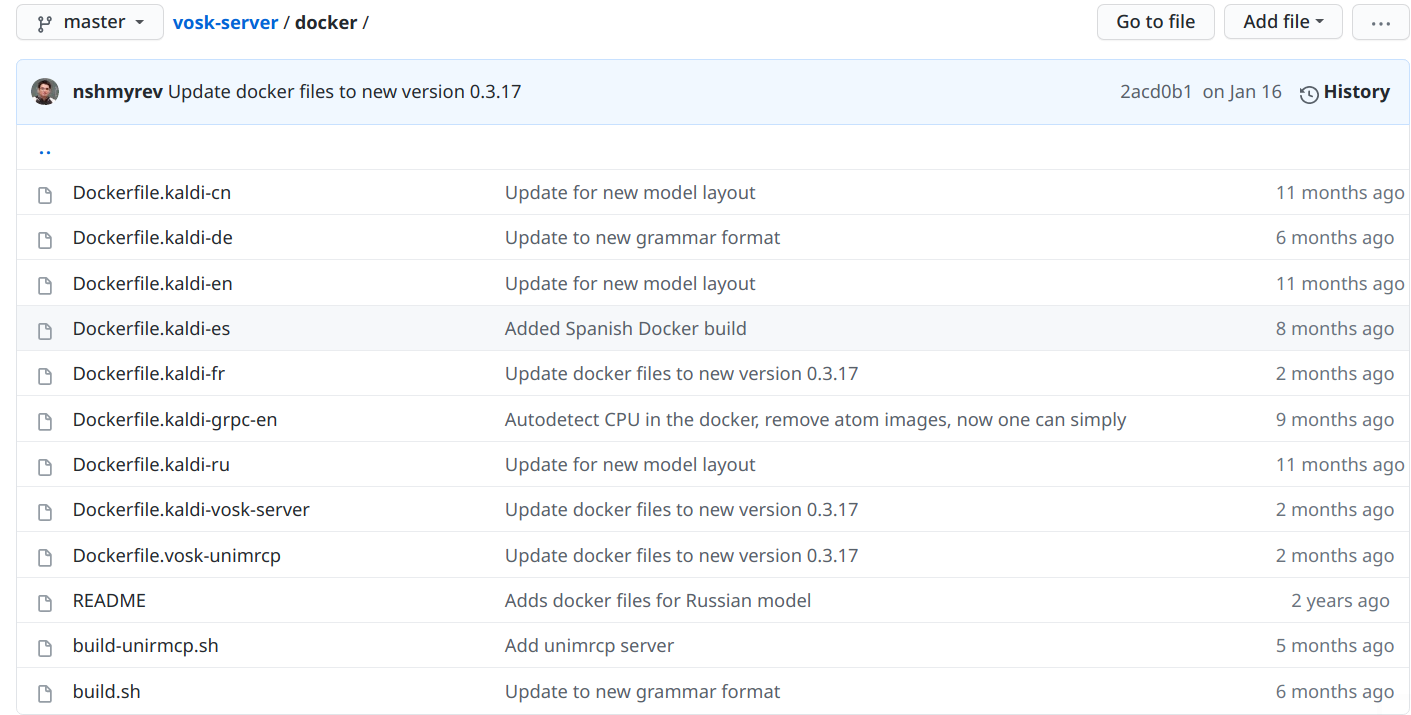
稍微遗憾的是,这上面提供的dockerfile目前在树莓派上是无法直接食用的。
值得高兴的是,在某一个commit中有人专门写了一个适用于arm平台的kaldi-vosk-server的Dockerfile: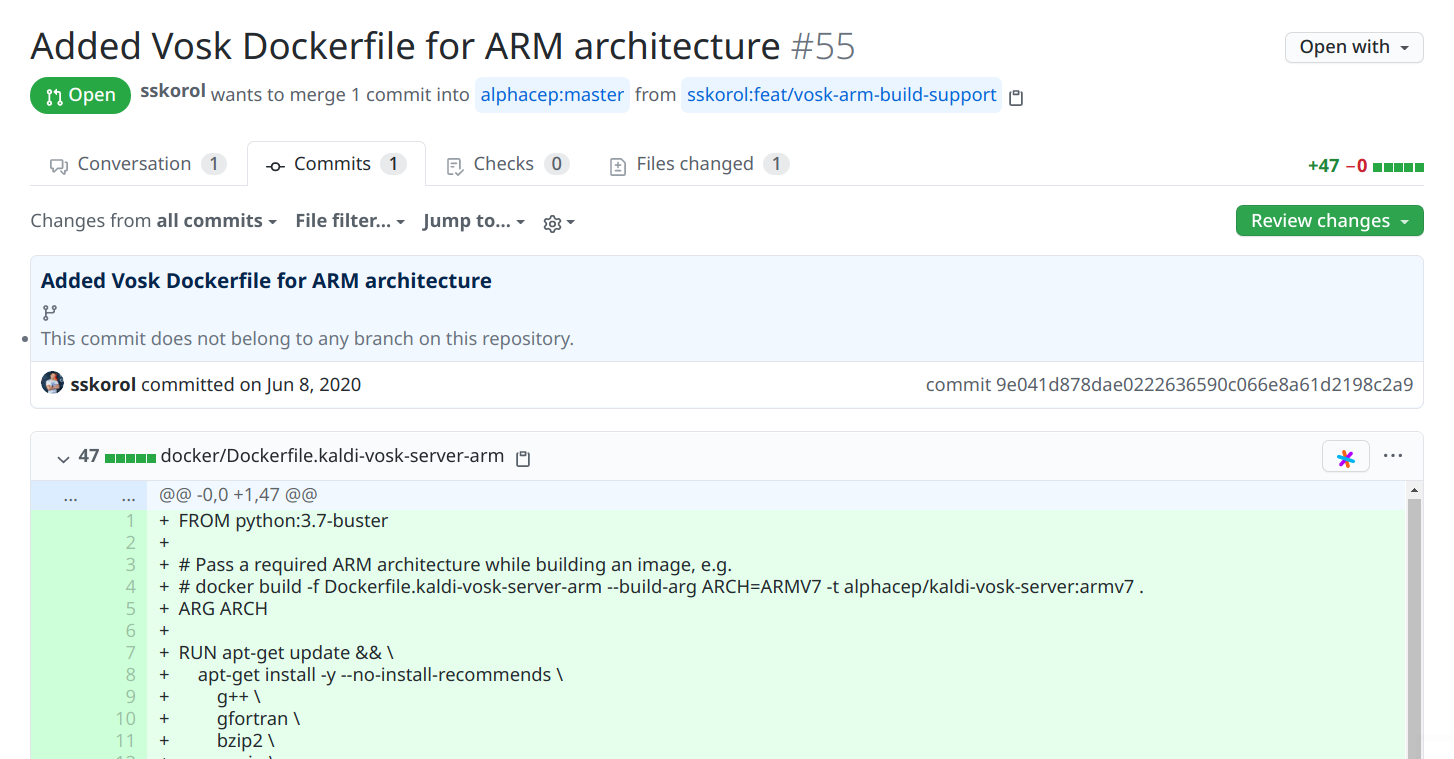
享受白嫖的乐趣!
由于我的树莓派安装的64位系统(raspios_arm64 or raspios_lite_arm64), 所以稍微改动一下, 最终的Dockerfile如下:
1 | FROM python:3.7-buster |
然后执行docker build:
1 | docker build -t alphacep/kaldi-vosk-server:armv8 . |
不出意外的话是会报以下错误的:
1 | g++: internal compiler error: Killed (program cc1plus) |
在编译过程中需要大量的内存, 而树莓派4的4G内存不够用(8G内存够用),解决方法是使用交换空间,
我创建一个4G大小的交换空间:
1 | sudo dd if=/dev/zero of=/swapfile bs=64M count=32 |
接下再执行docker build来编译vosk-server镜像,大概需要2小时。
build完成后,不再使用交换空间:
1 | sudo swapoff /swapfile |
接下来再基于上面的kaldi-vosk-server镜像制作vosk-server-cn镜像, 直接使用github上的Dockerfile会有一些问题, 运行报错提示缺少websocket,cffi等库,缺少libvosk.so文件等,
需要小改一下, 改动后的Dockerfile如下:
1 | FROM alphacep/kaldi-vosk-server:armv8 |
注: libvosk.so文件提取自适用于aarch64的vosk的python库,下载下来后解压,里面有一个libvosk.so文件。
执行docker build:
1 | docker build -t alphacep/kaldi-cn . |
build结束后docker images看一下是否有alphacep/kaldi-cn镜像:

docker run看看效果:
1 | docker run -d -p 2700:2700 alphacep/kaldi-cn:latest |
一切OK的话在树莓派上就跑起来了一个离线的语音识别服务了。
镜像减肥
通过上面的操作我们虽然搭建好了一个离线的识别服务, 但是这个镜像的体积是在是太大了, 有没有办法缩小一点呢?
这个镜像之所以这么大, 是因为在第一步编译kaldi-vosk-server时是从源码编译的, 源码和编译的中间产物占了不少的空间, 而运行起来之后是不需要的了。
可以通过docker export命令来保存一个容器的快照为镜像, 这样就没有docker build时的层和元数据了。假如以上我们运行起来vosk-server的容器ID为53d5f5d86f48,将该容器导出为镜像包:
1 | docker export 53d5f5d86f48 > docker_kaldi-cn.tar |
然后使用docker import命令导入该镜像:
1 | docker import - kaldi-cn:latest < docker_kaldi-cn.tar |
你会发现这样操作之后镜像大小减少到了1.3G!(这也为减少docker的镜像体积提供了一种思路)
而该镜像是无法直接run起来的,因为没有CMD,可以基于该镜像制作一个, Dockerfile如下:
1 | FROM kaldi-cn:latest |
docker build:
1 | docker build -t rpi-kaldi-cn:latest . |
my-kaldi-cn即为最终的镜像, 可使用docker run运行(先将之前运行的alphacep/kaldi-cn停掉):
1 | docker run -d -p 2700:2700 rpi-kaldi-cn:latest |
快速测试
在vosk-server项目中有python的代码可供测试(需安装pyaudio和websocket库):
1 | git clone https://github.com/alphacep/vosk-server |
通过以上方式,便在树莓派上使用docker部署了一个基于kaldi的离线语音识别服务,通过dockerfile编译出来的镜像体积太大, 我们通过导出容器的快照重新生成镜像的方式来减小了镜像的体积, 方便以后镜像的保存和传输。