作为学生来说,一学期免不了要跟教务系统打很多次交道, 相信每个学校的教务系统都会被吐槽一番。学校本着勤俭节约,能用就将就的原则,不对系统做优化,服务器不升级,一到选课巨卡。
作为计算机专业的学生,教务系统倒是拿来练手的好网站(当然不是渗透测试), 写个小爬虫,抓一抓课表什么的还是很不错的, 努点力甚至可以抓到全校学生(妹子)信息(勿试)!
我某天闲着无事,终于对教务系统下手了… 先定个小目标,模拟登录教务系统获取到个人基本信息。只要完成这一步,获取课表,甚至模拟抢课就是顺手牵羊的事,无非多花些精力分析一下抢课的接口。
登录请求分析
打开攀枝花学院教务系统,使用chrome浏览器,F12,打开开发者工具。输入学号密码验证码后点击登录,在开发者工具中的Network这里发现了POST地址(http://jwc.pzhu.cn/jwweb/_data/index_LOGIN.aspx)以及表单数据:
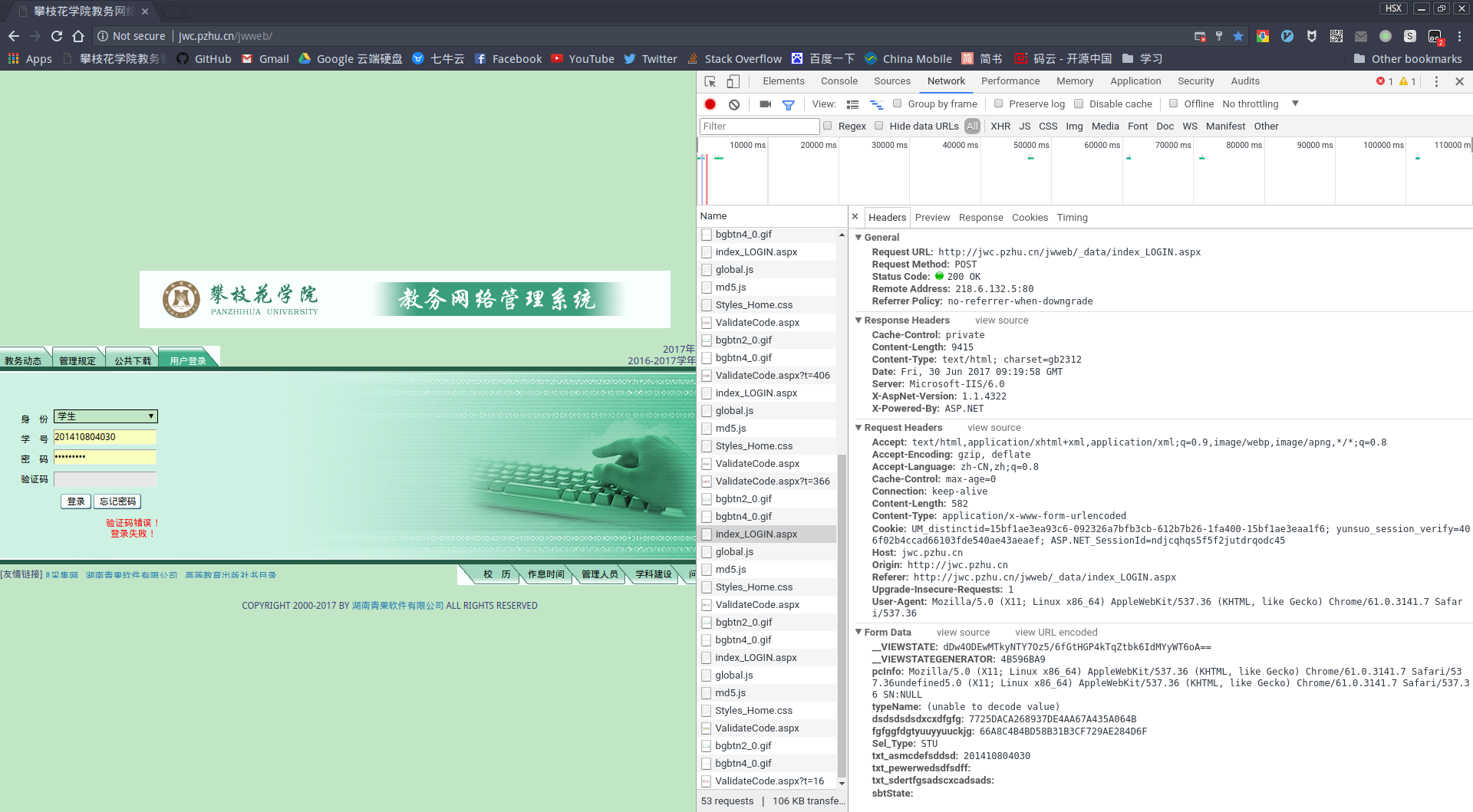
而在Form Data(表单数据)这一栏里并没有所期望的数据:
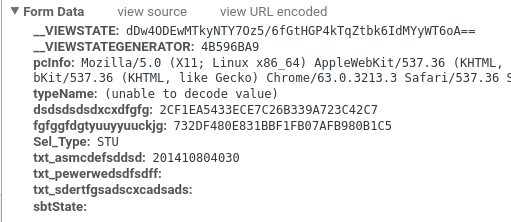
可以看到,需要POST的数据很多,而其中只有学号是明文的,而密码和验证码居然为空….看来教务系统对数据加了密的。而dsdsdsdsdxcxdfgfg和fgfggfdgtyuuyyuuckjg这两个表示的很有可能就是加密后的值。于是借助开发者工具,可以查看该网页的源码来找到加密方式。
在Sources这一栏里可以查看网页的源码,在index_LOGIN.aspx这个网页中发现了一些js函数
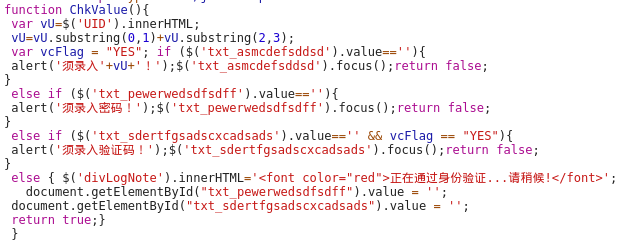
这里可以看到在用户身份验证成功后清空了密码框和验证码框的值,所以我们看到POST数据里密码和验证码是空的由此看来,一定是使用了密码和验证码组合加密,于是又继续在源代码里寻找加密方式。
很快,找到了一个比较隐秘的函数:

写在一行代码里的,不仔细看很难发现。
该代码如下:(这么长的代码写成一行真够居心叵测的….)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| function chkpwd(obj)
{
if(obj.value!='')
{
var s=md5(document.all.txt_asmcdefsddsd.value+md5(obj.value).substring(0,30).toUpperCase()+'11360').substring(0,30).toUpperCase();
document.all.dsdsdsdsdxcxdfgfg.value=s;
} else
{
document.all.dsdsdsdsdxcxdfgfg.value=obj.value;
}
}
function chkyzm(obj) {
if(obj.value!='') {
var s=md5(md5(obj.value.toUpperCase()).substring(0,30).toUpperCase()+'11360').substring(0,30).toUpperCase();
document.all.fgfggfdgtyuuyyuuckjg.value=s;
} else {
document.all.fgfggfdgtyuuyyuuckjg.value=obj.value.toUpperCase();
}
}
|
分析阅读该代码,chkpwd(obj)函数是加密密码的,chkyzm(obj)是加密验证码的。
chkpwd()函数:
该函数是对密码的加密,加密后的值为dsdsdsdsdxcxdfgfg对应的值
- 将输入的密码转换为MD5
- 取0-29位的值再将全部字母转换为大写
- 然后加上学号和字符串’11360’
- 再转换为MD5,取0-29位,再将全部字母转换为大写。
chkyzm()函数:
该函数是对验证码加密,加密后的值为fgfggfdgtyuuyyuuckjg
- 将验证码全部字母转换为大写
- 然后进行MD5加密,取0-29位字符,全部字母转换为大写
- 加上字符串“11360”,再MD5加密,取0-29位字符,全部字母转为大写。
弄清了加密方式后,就可以用Python复现加密操作了。
下面的代码实现了上面分析的chkpwd()加密方式,学号201410804030,密码123456:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def MD5(s):
s = s.encode('gb2312')
m2 = hashlib.md5()
m2.update(s)
return m2.hexdigest()
def chkpw(s):
pw_temp = str(MD5(s))[0:30].upper()+"11360"
res = str(MD5(StudentNum+pw_temp)[0:30]).upper()
return res
def chkyzm(s):
yzm_temp = MD5(MD5(str(s).upper())[0:30].upper()+"11360")[0:30]
res = yzm_temp.upper()
return res
|
js加密方式搞定以后,还需要获取到验证码,因为是把验证码和密码一起加密的。
首先还是打开开发者工具,很容易就能找到验证码的地址:
1
| http://jwc.pzhu.cn/jwweb/sys/ValidateCode.aspx
|
验证码需要带着cookie取获取,直接访问验证码url会获取失败。
思路是先访问教务系统主页,获取到cookie, 带着cookie去访问验证码url获取验证码。
使用requests库的session能保留每次的请求会话,能很方便的完成上述操作。
以下便是获取验证码的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
import requests
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
jwurl = "http://jwc.pzhu.cn/jwweb/"
LoginUrl = jwurl+"_data/index_LOGIN.aspx"
ValidateCodeUrl=jwurl+"sys/ValidateCode.aspx"
def Headers(URL):
Base_Headers = {
"Content-Type": "application/x-www-form-urlencoded",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
}
if URL == 'HOME':
Base_Headers["Referer"]=jwurl
return Base_Headers
elif URL == 'LOGIN':
Base_Headers["Referer"]=LoginUrl
return Base_Headers
return Base_Headers
session = requests.session()
def Get_vcode():
print("正在获取验证码...")
session.get(url=jwurl, headers=Headers('HOME'))
session.get(url=LoginUrl, headers=Headers('LOGIN'))
response = session.get(url = ValidateCodeUrl, headers = Headers('LOGIN'))
if response.status_code == 200:
with open('Verificationpic.jpg','wb') as f :
f.write(response.content)
print("验证码保存为当前目录下的Verificationpic.jpg")
else:
print("验证码获取失败,请确保网络通畅或者请重试")
Get_vcode()
yzm = input("请输入验证码:")
|
验证码图片会下载到当前目录, 程序会等待输入, 需要打开图片手动将验证码输入到程序里.
之后按照上面的加密逻辑,将验证码和密码加密后的结果与用户名构造post请求,模拟登录。
pwd和yzm为通过以上两个加密函数加密处理后的结果,构造登录post表单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def Post_Data(pwd, yzm):
post_data = {
'__VIEWSTATE': 'dDw4ODEwMTkyNTY7Oz5/6fGtHGP4kTqZtbk6IdMYyWT6oA==',
'__VIEWSTATEGENERATOR': '4B596BA9',
'pcInfo': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3213.3 Safari/537.36undefined5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3213.3 Safari/537.36 SN:NULL',
'typeName': u"学生".encode('gb2312'),
'dsdsdsdsdxcxdfgfg': pwd,
'fgfggfdgtyuuyyuuckjg': yzm,
'Sel_Type': 'STU',
'txt_asmcdefsddsd': '201410804030',
'txt_pewerwedsdfsdff': ' ',
'txt_sdertfgsadscxcadsads': ' ',
'sbtState': ' '
}
return post_data
|
模拟登录:
1
2
3
4
5
6
7
8
9
10
| def Login(pwd, yzm):
response = session.post(url=LoginUrl, data=Post_Data(pwd, yzm), headers=Headers('LOGIN') )
if re.search( u"正在加载权限", response.text ):
print( u"登录成功,请稍等...\n" )
elif re.search ( u"帐号或密码不正确", response.text ):
print( u"账号或密码不正确,请重试\n" )
elif re.search ( u"验证码错误", response.text ):
print( u"验证码不正确,请重试\n" )
else:
print( u"抱歉,登录出错\n" )
|
不出意外便能顺利登录进去。
同样通过分析,个人信息的url为:
1
| http://jwc.pzhu.cn/jwweb/xsxj/Stu_MyInfo_RPT.aspx
|
这个时候我们已经登录进去了, 直接拿着登录后的session去访问这个url就能获取到个人信息了,
使用xpath能方便的解析网页数据,最后将解析出来的数据保存下来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| def Get_userInfo():
comfirm_num = input("确认获取你的基本信息?\n确认请按Y/y(es),离开请按任意键:")
print("\n")
if comfirm_num == "y" or comfirm_num == "Y" or comfirm_num == "yes":
Base_Info = session.get (url = UserInfoUrl,headers = Headers('LOGIN'))
Base_Info_text = Base_Info.text
photo_re_url = re.findall(r"(?<=src=\'../).+?(?=\')",Base_Info_text,re.I|re.S|re.M)
photo_url = jwurl+photo_re_url[0]
selector = html.fromstring(Base_Info_text)
User_Name = selector.xpath('//table/tr[2]/td[4]/text()')[0].decode("utf-8")
User_Num = selector.xpath('//table/tr[2]/td[2]/text()')[0].decode("utf-8")
User_Gender = selector.xpath('//table/tr[4]/td[2]/text()')[0].decode("utf-8")
User_ID = selector.xpath('//table/tr[4]/td[4]/text()')[0].decode("utf-8")
User_Birth = selector.xpath('//table/tr[5]/td[2]/text()')[0].decode("utf-8")
User_Famous = selector.xpath('//table/tr[5]/td[4]/text()')[0].decode("utf-8")
User_Local = selector.xpath('//table/tr[6]/td[2]/text()')[0].decode("utf-8")
User_Adress = selector.xpath('//table/tr[10]/td[4]/text()')[0].decode("utf-8")
User_Cee_Num = selector.xpath('//table/tr[13]/td[4]/text()')[0].decode("utf-8")
User_Cee_score = selector.xpath('//table/tr[18]/td[2]/text()')[0].decode("utf-8")
User_Adnission_Time = selector.xpath('//table/tr[19]/td[2]/text()')[0].decode("utf-8")
User_Faculty = selector.xpath('//table/tr[24]/td[2]/text()')[0].decode("utf-8")
User_Profession = selector.xpath('//table/tr[24]/td[4]/text()')[0].decode("utf-8")
User_Class = selector.xpath('//table/tr[24]/td[6]/text()')[0].decode("utf-8")
User_Teacher = selector.xpath('//table/tr[25]/td[2]/text()')[0].decode("utf-8")
|
以上,就完成了模拟登录教务系统并获取里面的数据(个人信息), 同理, 分析出了课表或者抢课的接口,
就能很快的写一个下载课表工具或者抢课工具.
在获取个人照片的过程中,我注意到个人照片的url可以直接访问到,不需要登录, 但是url是由学号+随机字符串组成, 通过遍历穷举的方式来获取全校同学的照片的难度大大增加…
完整代码见:爬取攀枝花学院教务系统个人信息